Reinforcement Learning
Besides MARL, we also pay attention to the fundamentals of reinforcement learning including the tradeoff between exploration and exploitation, and experience replay for off-policy RL.
GENE
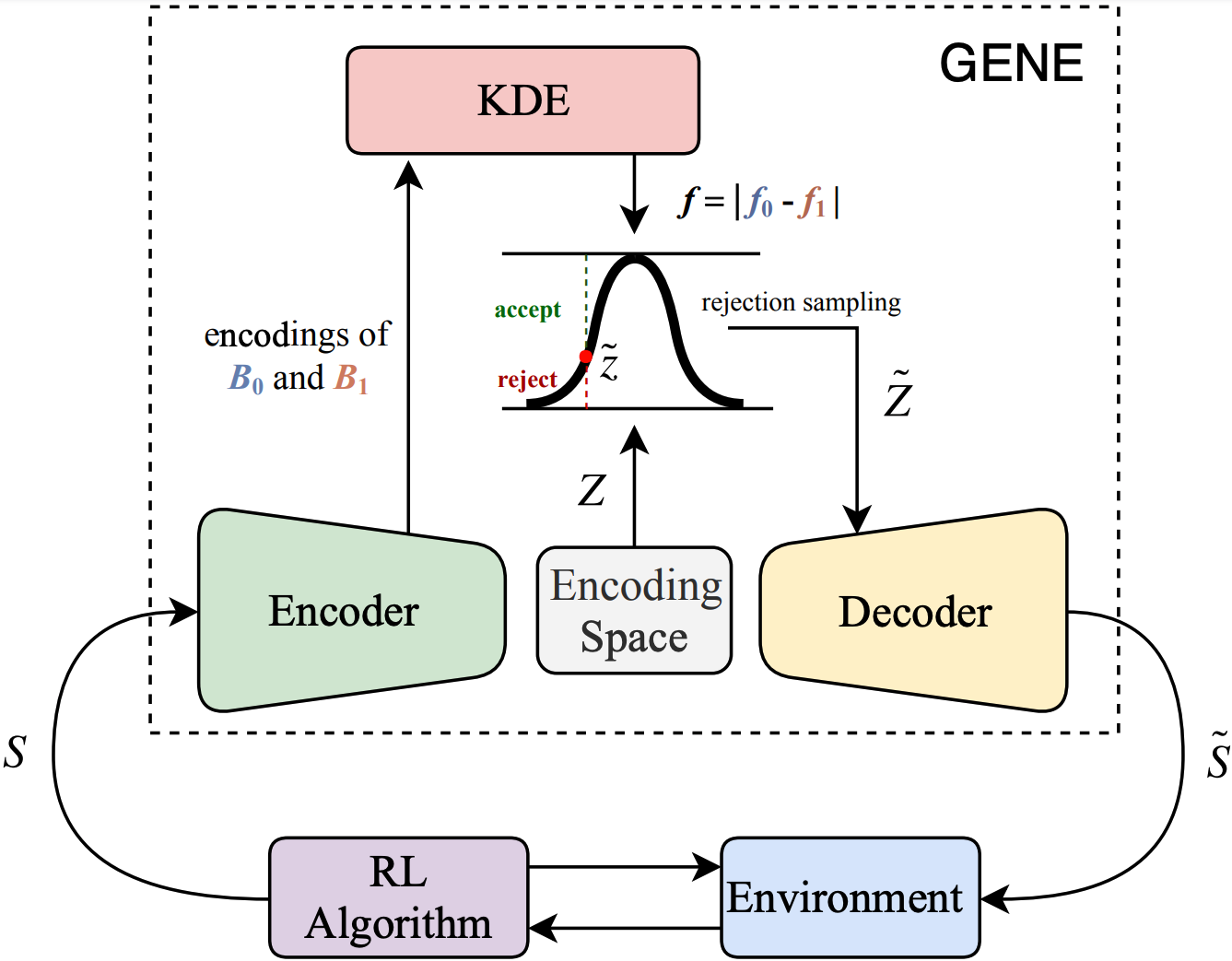 Sparse reward is one of the biggest challenges in RL. We propose a novel method called Generative Exploration and Exploitation (GENE) to overcome sparse reward. GENE dynamically changes the start state of agent to the generated novel state to encourage the agent to explore the environment or to the generated rewarding state to boost the agent to exploit the received reward signal. GENE relies on no prior knowledge about the environment and can be combined with any RL algorithm, no matter on-policy or off-policy, single-agent or multi-agent. Empirically, we demonstrate that GENE significantly outperforms existing methods in four challenging tasks with only binary rewards indicating whether or not the task is completed, including Maze, Goal Ant, Pushing, and Cooperative Navigation. The ablation studies verify that GENE can adaptively tradeoff between exploration and exploitation as the learning progresses by automatically adjusting the proportion between generated novel states and rewarding states, which is the key for GENE to solving these challenging tasks effectively and efficiently.
Sparse reward is one of the biggest challenges in RL. We propose a novel method called Generative Exploration and Exploitation (GENE) to overcome sparse reward. GENE dynamically changes the start state of agent to the generated novel state to encourage the agent to explore the environment or to the generated rewarding state to boost the agent to exploit the received reward signal. GENE relies on no prior knowledge about the environment and can be combined with any RL algorithm, no matter on-policy or off-policy, single-agent or multi-agent. Empirically, we demonstrate that GENE significantly outperforms existing methods in four challenging tasks with only binary rewards indicating whether or not the task is completed, including Maze, Goal Ant, Pushing, and Cooperative Navigation. The ablation studies verify that GENE can adaptively tradeoff between exploration and exploitation as the learning progresses by automatically adjusting the proportion between generated novel states and rewarding states, which is the key for GENE to solving these challenging tasks effectively and efficiently.
VER
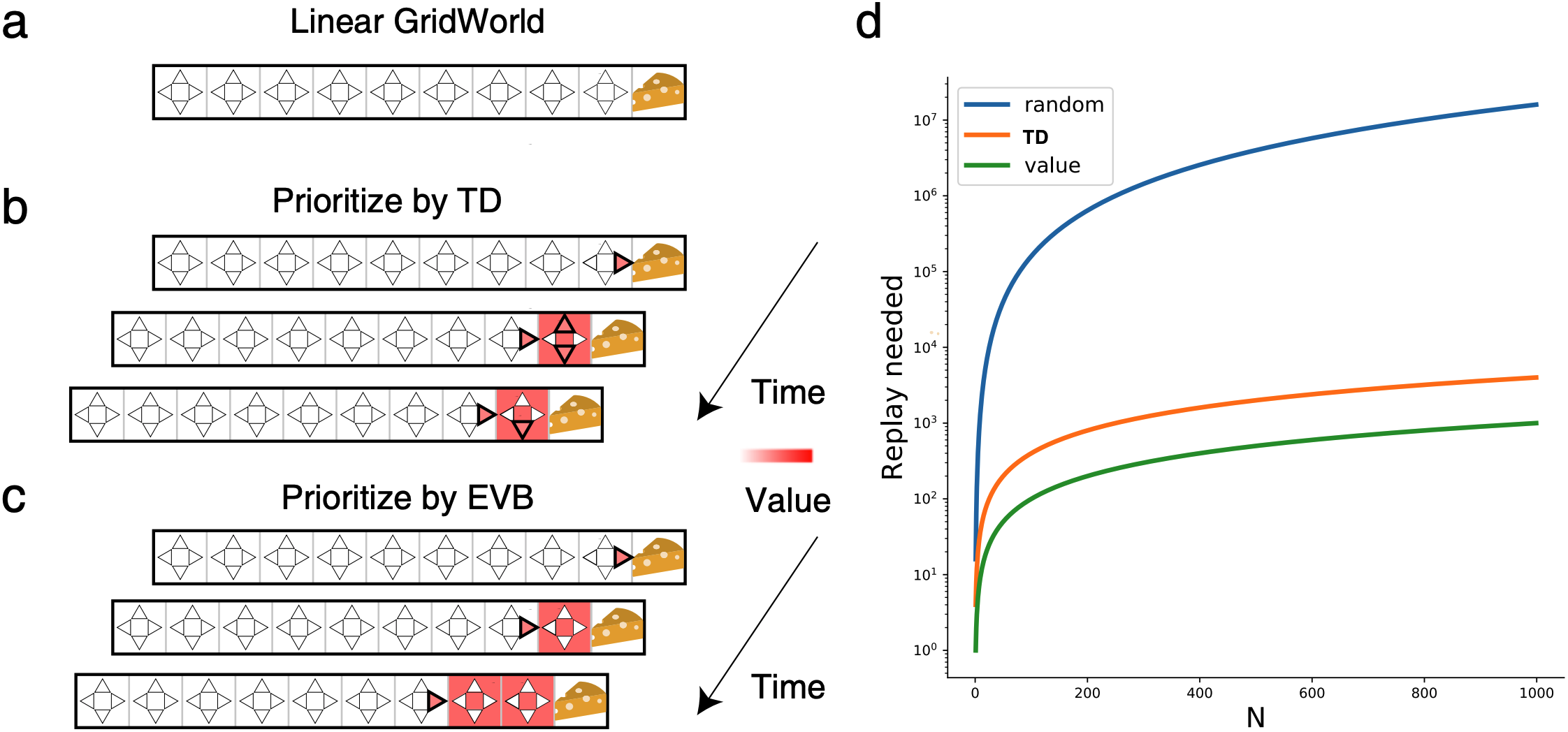 Experience replay enables off-policy RL agents to utilize past experiences to maximize the cumulative reward. Prioritized experience replay that weighs experiences by the magnitude of their temporal-difference error (|TD|) significantly improves the learning efficiency. But how |TD| is related to the importance of experience is not well understood. We address this problem from an economic perspective, by linking |TD| to value of experience, which is defined as the value added to the cumulative reward by accessing the experience. We theoretically show the value metrics of experience are upper-bounded by |TD| for Q-learning. Furthermore, we successfully extend our theoretical framework to maximum-entropy RL by deriving the lower and upper bounds of these value metrics for soft Q-learning, which turn out to be the product of |TD| and “on-policyness” of the experiences. Our framework links two important quantities in RL: |TD| and value of experience. We empirically show that the bounds hold in practice, and experience replay using the upper bound as priority improves maximum-entropy RL in Atari games.
Experience replay enables off-policy RL agents to utilize past experiences to maximize the cumulative reward. Prioritized experience replay that weighs experiences by the magnitude of their temporal-difference error (|TD|) significantly improves the learning efficiency. But how |TD| is related to the importance of experience is not well understood. We address this problem from an economic perspective, by linking |TD| to value of experience, which is defined as the value added to the cumulative reward by accessing the experience. We theoretically show the value metrics of experience are upper-bounded by |TD| for Q-learning. Furthermore, we successfully extend our theoretical framework to maximum-entropy RL by deriving the lower and upper bounds of these value metrics for soft Q-learning, which turn out to be the product of |TD| and “on-policyness” of the experiences. Our framework links two important quantities in RL: |TD| and value of experience. We empirically show that the bounds hold in practice, and experience replay using the upper bound as priority improves maximum-entropy RL in Atari games.