Multi-Agent Reinforcement Learning (MARL) has recently attracted much attention from the communities of machine learning, artificial intelligence, and multi-agent systems. As an interdisciplinary research field, there are so many unsolved problems, from cooperation to competition, from agent communication to agent modeling, from centralized learning to decentralized learning. MARL has been the main research focus of our lab. We are investigating the field from many perspectives. In the following, we introduce some of our studies. For detail, please refer to the papers.
RL/Multi-Agent RL
Cooperation
Cooperation has been one of the major research topics in MARL. We investigate multi-agent cooperation from many aspects, including adaptive learning rates, reward sharing, roles, and fairness.
FEN
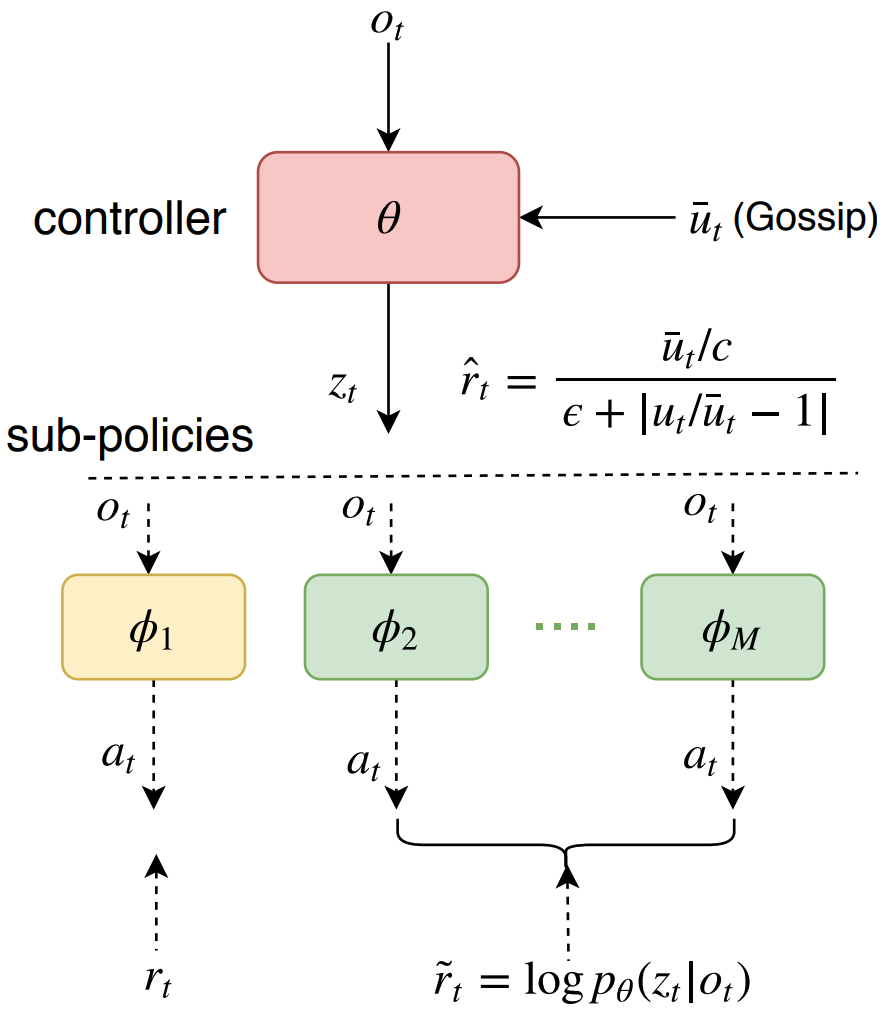 Fairness is essential for human society, contributing to stability and productivity. Similarly, fairness is also the key for many multi-agent systems. Taking fairness into multi-agent learning could help multi-agent systems become both efficient and stable. However, learning efficiency and fairness simultaneously is a complex, multi-objective, joint-policy optimization. To tackle these difficulties, we propose FEN, a novel hierarchical reinforcement learning model. We first decompose fairness for each agent and propose fair-efficient reward that each agent learns its own policy to optimize. To avoid multi-objective conflict, we design a hierarchy consisting of a controller and several sub-policies, where the controller maximizes the fair-efficient reward by switching among the sub-policies that provides diverse behaviors to interact with the environment. FEN can be trained in a fully decentralized way, making it easy to be deployed in real-world applications. Empirically, we show that FEN easily learns both fairness and efficiency and significantly outperforms baselines in a variety of multi-agent scenarios.
Fairness is essential for human society, contributing to stability and productivity. Similarly, fairness is also the key for many multi-agent systems. Taking fairness into multi-agent learning could help multi-agent systems become both efficient and stable. However, learning efficiency and fairness simultaneously is a complex, multi-objective, joint-policy optimization. To tackle these difficulties, we propose FEN, a novel hierarchical reinforcement learning model. We first decompose fairness for each agent and propose fair-efficient reward that each agent learns its own policy to optimize. To avoid multi-objective conflict, we design a hierarchy consisting of a controller and several sub-policies, where the controller maximizes the fair-efficient reward by switching among the sub-policies that provides diverse behaviors to interact with the environment. FEN can be trained in a fully decentralized way, making it easy to be deployed in real-world applications. Empirically, we show that FEN easily learns both fairness and efficiency and significantly outperforms baselines in a variety of multi-agent scenarios.
AdaMa
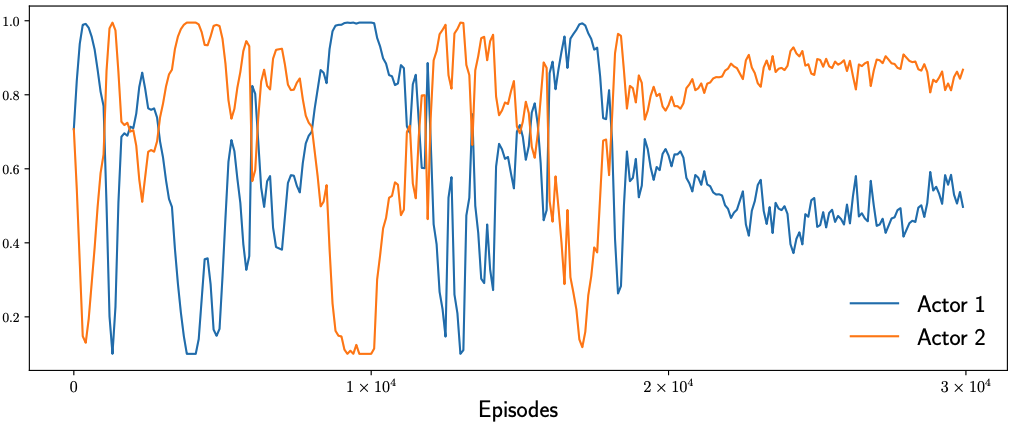 In multi-agent reinforcement learning (MARL), the learning rates of actors and critic are mostly hand-tuned and fixed. This not only requires heavy tuning but more importantly limits the learning. With adaptive learning rates according to gradient patterns, some optimizers have been proposed for general optimizations, which however do not take into consideration the characteristics of MARL. We propose AdaMa to bring adaptive learning rates to cooperative MARL. AdaMa evaluates the contribution of actors’ updates to the improvement of Q-value and adaptively updates the learning rates of actors to the direction of maximally improving the Q-value. AdaMa could also dynamically balance the learning rates between the critic and actors according to their varying effects on the learning. Moreover, AdaMa can incorporate the second-order approximation to capture the contribution of pairwise actors’ updates and thus more accurately updates the learning rates of actors. Empirically, we show that AdaMa could accelerate the learning and improve the performance in a variety of multi-agent scenarios. Specifically, AdaMa not only obtains better performance than grid search on the learning rates, but also significantly reduces the training cost. The visualizations of learning rates during training clearly explain how and why AdaMa works.
In multi-agent reinforcement learning (MARL), the learning rates of actors and critic are mostly hand-tuned and fixed. This not only requires heavy tuning but more importantly limits the learning. With adaptive learning rates according to gradient patterns, some optimizers have been proposed for general optimizations, which however do not take into consideration the characteristics of MARL. We propose AdaMa to bring adaptive learning rates to cooperative MARL. AdaMa evaluates the contribution of actors’ updates to the improvement of Q-value and adaptively updates the learning rates of actors to the direction of maximally improving the Q-value. AdaMa could also dynamically balance the learning rates between the critic and actors according to their varying effects on the learning. Moreover, AdaMa can incorporate the second-order approximation to capture the contribution of pairwise actors’ updates and thus more accurately updates the learning rates of actors. Empirically, we show that AdaMa could accelerate the learning and improve the performance in a variety of multi-agent scenarios. Specifically, AdaMa not only obtains better performance than grid search on the learning rates, but also significantly reduces the training cost. The visualizations of learning rates during training clearly explain how and why AdaMa works.
Publications
[NIPS'19] Learning Fairness in Multi-Agent Systems
Thirty-Third Annual Conference on Neural Information Processing Systems (NIPS), December 8-14, 2019.
(Acceptance Rate: 21%=1428⁄6743)
[ICML'21] FOP: Factorizing Optimal Joint Policy of Maximum-Entropy Multi-Agent Reinforcement Learning
Thirty-Eighth International Conference on Machine Learning (ICML), July 18-24, 2021
(Acceptance Rate: 21%=1184⁄5513)
[ICML'21] The Emergence of Individuality
Thirty-Eighth International Conference on Machine Learning (ICML), July 18-24, 2021
(Acceptance Rate: 3%=166⁄5513, oral presentation)
[ICML'22] Difference Advantage Estimation for Multi-Agent Policy Gradients
Thirty-Ninth International Conference on Machine Learning (ICML), July 17-23, 2022
(Acceptance Rate: 22%=1235⁄5630)
[ICML'22] Divergence-Regularized Multi-Agent Actor-Critic
Thirty-Ninth International Conference on Machine Learning (ICML), July 17-23, 2022
(Acceptance Rate: 22%=1235⁄5630)
[NIPS'22] Model-Based Opponent Modeling
Thirty-Sixth Annual Conference on Neural Information Processing Systems (NIPS), November 28 - December 9, 2022.
(Acceptance Rate: 25.6%=2665⁄10411)
[NIPS'22] I2Q: A Fully Decentralized Q-Learning Algorithm
Thirty-Sixth Annual Conference on Neural Information Processing Systems (NIPS), November 28 - December 9, 2022.
(Acceptance Rate: 25.6%=2665⁄10411)
[AAAI'23] Online Tuning for Offline Decentralized Multi-Agent Reinforcement Learning
Thirty-Seventh AAAI Conference on Artificial Intelligence (AAAI), February 7-14, 2023.
(Acceptance Rate: 19%=1721⁄8777)
[AAMAS'23] Adaptive Learning Rates for Multi-Agent Reinforcement Learning
Twenty-Second International Conference on Autonomous Agents and Multiagent Systems (AAMAS), May 29 - June 2, 2023.
(Acceptance Rate: 23%=237⁄1015)
[ICLR'23] More Centralized Training, Still Decentralized Execution: Multi-Agent Conditional Policy Factorization
Eleventh International Conference on Learning Representations (ICLR), May 1-5, 2023.
[ECAI'23] Offline Decentralized Multi-Agent Reinforcement Learning
26th European Conference on Artificial Intelligence (ECAI), Sept. 30-Oct. 4, 2023.
(Acceptance Rate: 24%=391⁄1631)
[NeurIPS'23] Mutual-Information Regularized Multi-Agent Policy Iteration
Thirty-Seventh Conference on Neural Information Processing Systems (NeurIPS), Dec. 10-16, 2023.
(Acceptance Rate: 26.1%=3221⁄12343)
[AAAI'24] Settling Decentralized Multi-Agent Coordinated Exploration by Novelty Sharing
Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI), February 20-27, 2024
(Acceptance Rate: 23.75%=2342⁄9862)
[AAMAS'24] Multi-Agent Alternate Q-Learning
Twenty-Third International Conference on Autonomous Agents and Multiagent Systems (AAMAS), May 6-10.
(Acceptance Rate: 25%=229⁄883)
[TMLR] A Fully Decentralized Surrogate for Multi-Agent Policy Optimization
Transactions on Machine Learning Research (TMLR), 2024
[NeurIPS'24] A Novel Benchmark for Decision-Making in Uncertain and Competitive Games
Thirty-Eighth Conference on Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks, Dec. 9-15, 2024.
(Acceptance Rate: 25.3%, spotlight)
[NeurIPS'24] Opponent Modeling based on Subgoal Inference
Thirty-Eighth Conference on Neural Information Processing Systems (NeurIPS), Dec. 9-15, 2024.
(Acceptance Rate: 25.8%)
[TMLR] $f$-Divergence Policy Optimization in Fully Decentralized Cooperative MARL
Transactions on Machine Learning Research (TMLR), 2025
[ICML'25] Revisiting Cooperative Off-Policy Multi-Agent Reinforcement Learning
Forty-Second International Conference on Machine Learning (ICML), July 13-19, 2025
(Acceptance Rate: 26.9%=3260⁄12107)
[UAI'25] Best Possible Q-Learning
Conference on Uncertainty in Artificial Intelligence (UAI), July 21-25, 2025.
(Acceptance Rate: 30.7%=230⁄750)
[NeurIPS'25] Planning with Quantized Opponent Models
Thirty-Ninth Conference on Neural Information Processing Systems (NeurIPS), Dec. 2-7, 2025.
(Acceptance Rate: 24.52%)
[ICLR'26] Multi-Agent Guided Policy Optimization
International Conference Learning Representations (ICLR), 2026
Agent Communication
Biologically, communication is closely related to and probably originated from cooperation. For example, vervet monkeys can make different vocalizations to warn other members of the group about different predators. Similarly, communication can be crucially important in MARL for cooperation, especially for the scenarios where a large number of agents work in a collaborative way, such as autonomous vehicles planning, smart grid control, and multi-robot control. Communication enables agents to behave collaboratively.
ATOC
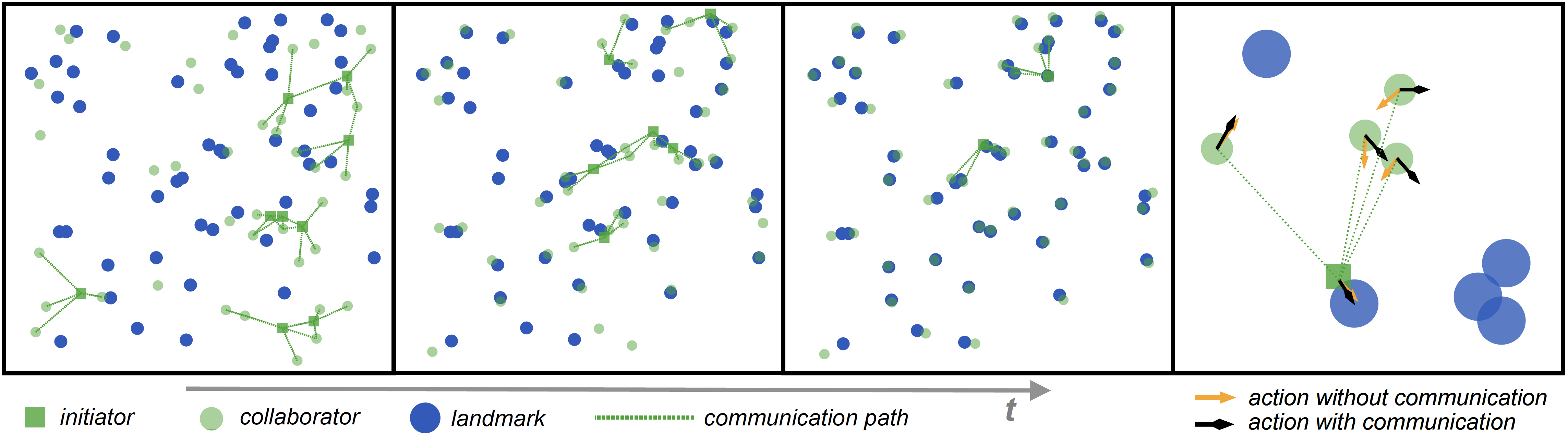
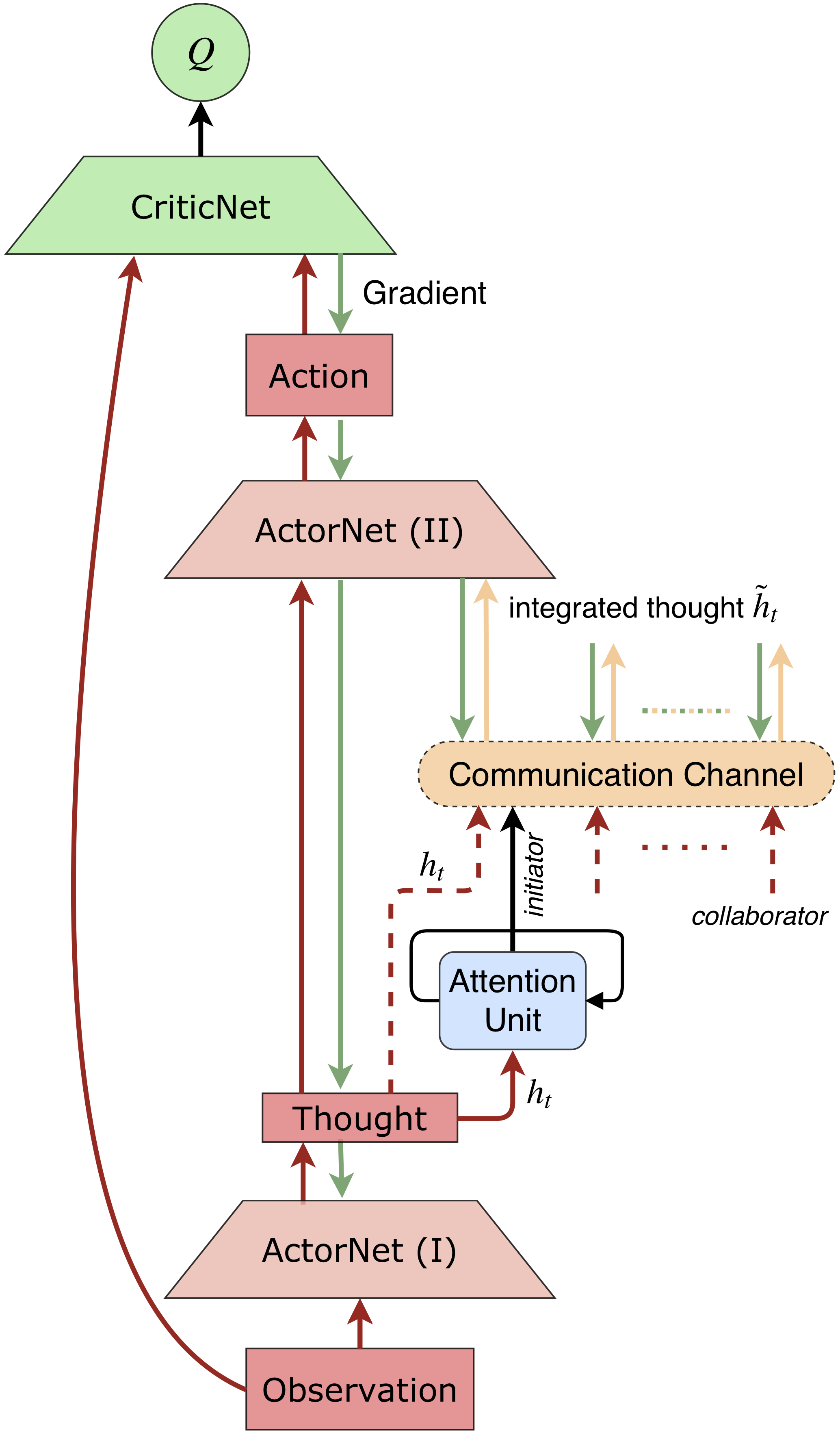 There are several approaches for learning communication in MARL. However, information sharing among all agents or in predefined communication architectures that existing methods adopt can be problematic. When there is a large number of agents, agents hardly differentiate valuable information that helps cooperative decision making from globally shared information, and hence communication barely helps and could even jeopardize the learning of cooperation. Moreover, in real-world applications, it is costly that all agents communicate with each other, since receiving a large amount of information requires high bandwidth and incurs long delay and high computational complexity. Predefined communication architectures might help, however they restrict communication among specific agents and thus restrain potential cooperation. To tackle these difficulties, we propose an attentional communication model, ATOC, to enable agents to learn effective and efficient communication under partially observable distributed environment for large-scale MARL. Inspired by recurrent models of visual attention, we design an attention unit that receives encoded local observation and action intention of an agent and determines whether the agent should communicate with other agents to cooperate in its observable field. If so, the agent, called initiator, selects collaborators to form a communication group for coordinated strategies. The communication group dynamically changes and retains only when necessary. We exploit a bi-directional LSTM unit as the communication channel to connect each agent within a communication group. The LSTM unit takes as input internal states and returns thoughts that guide agents for coordinated strategies. The LSTM unit selectively outputs important information for cooperative decision making, which makes it possible for agents to learn coordinated strategies in dynamic communication environments. ATOC agents are able to develop coordinated and sophisticated strategies in various cooperation scenarios.
There are several approaches for learning communication in MARL. However, information sharing among all agents or in predefined communication architectures that existing methods adopt can be problematic. When there is a large number of agents, agents hardly differentiate valuable information that helps cooperative decision making from globally shared information, and hence communication barely helps and could even jeopardize the learning of cooperation. Moreover, in real-world applications, it is costly that all agents communicate with each other, since receiving a large amount of information requires high bandwidth and incurs long delay and high computational complexity. Predefined communication architectures might help, however they restrict communication among specific agents and thus restrain potential cooperation. To tackle these difficulties, we propose an attentional communication model, ATOC, to enable agents to learn effective and efficient communication under partially observable distributed environment for large-scale MARL. Inspired by recurrent models of visual attention, we design an attention unit that receives encoded local observation and action intention of an agent and determines whether the agent should communicate with other agents to cooperate in its observable field. If so, the agent, called initiator, selects collaborators to form a communication group for coordinated strategies. The communication group dynamically changes and retains only when necessary. We exploit a bi-directional LSTM unit as the communication channel to connect each agent within a communication group. The LSTM unit takes as input internal states and returns thoughts that guide agents for coordinated strategies. The LSTM unit selectively outputs important information for cooperative decision making, which makes it possible for agents to learn coordinated strategies in dynamic communication environments. ATOC agents are able to develop coordinated and sophisticated strategies in various cooperation scenarios.
I2C
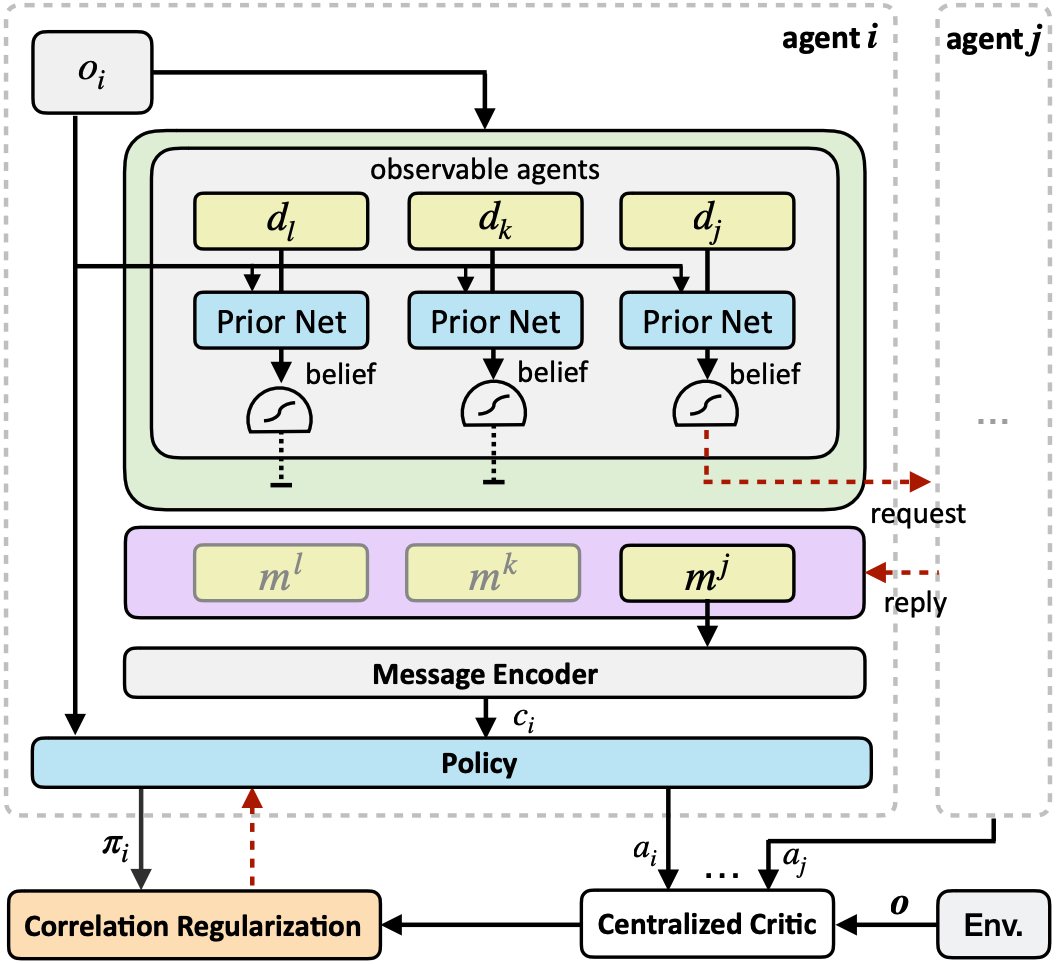 Most existing work of multi-agent communication focuses on broadcast communication, which is not only impractical but also leads to information redundancy that could even impair the learning process. To tackle these difficulties, we propose Individually Inferred Communication (I2C), a simple yet effective model to enable agents to learn a prior for agent-agent communication. The prior knowledge is learned via causal inference and realized by a feed-forward neural network that maps the agent’s local observation to a belief about who to communicate with. The influence of one agent on another is inferred via the joint action-value function in multi-agent reinforcement learning and quantified to label the necessity of agent-agent communication. Furthermore, the agent policy is regularized to better exploit communicated messages. Empirically, we show that I2C can not only reduce communication overhead but also improve the performance in a variety of multi-agent cooperative scenarios, comparing to existing methods.
Most existing work of multi-agent communication focuses on broadcast communication, which is not only impractical but also leads to information redundancy that could even impair the learning process. To tackle these difficulties, we propose Individually Inferred Communication (I2C), a simple yet effective model to enable agents to learn a prior for agent-agent communication. The prior knowledge is learned via causal inference and realized by a feed-forward neural network that maps the agent’s local observation to a belief about who to communicate with. The influence of one agent on another is inferred via the joint action-value function in multi-agent reinforcement learning and quantified to label the necessity of agent-agent communication. Furthermore, the agent policy is regularized to better exploit communicated messages. Empirically, we show that I2C can not only reduce communication overhead but also improve the performance in a variety of multi-agent cooperative scenarios, comparing to existing methods.
Publications
[NIPS'18] Learning Attentional Communication for Multi-Agent Cooperation
Thirty-Second Annual Conference on Neural Information Processing Systems (NIPS), December 3-8, 2018.
(Acceptance Rate: 21%=1011⁄4856)
[ICLR'20] Graph Convolutional Reinforcement Learning
International Conference on Learning Representation (ICLR), April 26-30, 2020.
(Acceptance Rate: 26.5%=687⁄2594)
[NIPS'20] Learning Individually Inferred Communication for Multi-Agent Cooperation
Thirty-Fourth Annual Conference on Neural Information Processing Systems (NIPS), December 6-12, 2020.
(Acceptance Rate: 1%=105⁄9454, oral)
[NIPS'22] Learning to Share in Multi-Agent Reinforcement Learning
Thirty-Sixth Annual Conference on Neural Information Processing Systems (NIPS), November 28 - December 9, 2022.
(Acceptance Rate: 25.6%=2665⁄10411)
[ICML'23] Entity Divider with Language Grounding in Multi-Agent Reinforcement Learning
Fortieth International Conference on Machine Learning (ICML), July 23-29, 2023.
(Acceptance Rate: 27.9%=1827⁄6538)
[ACL'23] Multi-Agent Language Learning: Symbolic Mapping
61st Annual Meeting of the Association for Computational Linguistics (ACL), Findings, July 9-14, 2023.
[AAAI'24] Learning Multi-Object Positional Relationships via Emergent Communication
Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI), February 20-27, 2024
(Acceptance Rate: 23.75%=2342⁄9862)
[NeurIPS'24] Multi-Agent Coordination via Multi-Level Communication
Thirty-Eighth Conference on Neural Information Processing Systems (NeurIPS), Dec. 9-15, 2024.
(Acceptance Rate: 25.8%)
Reinforcement Learning
Besides MARL, we also pay attention to the fundamentals of reinforcement learning including the tradeoff between exploration and exploitation, and experience replay for off-policy RL.
GENE
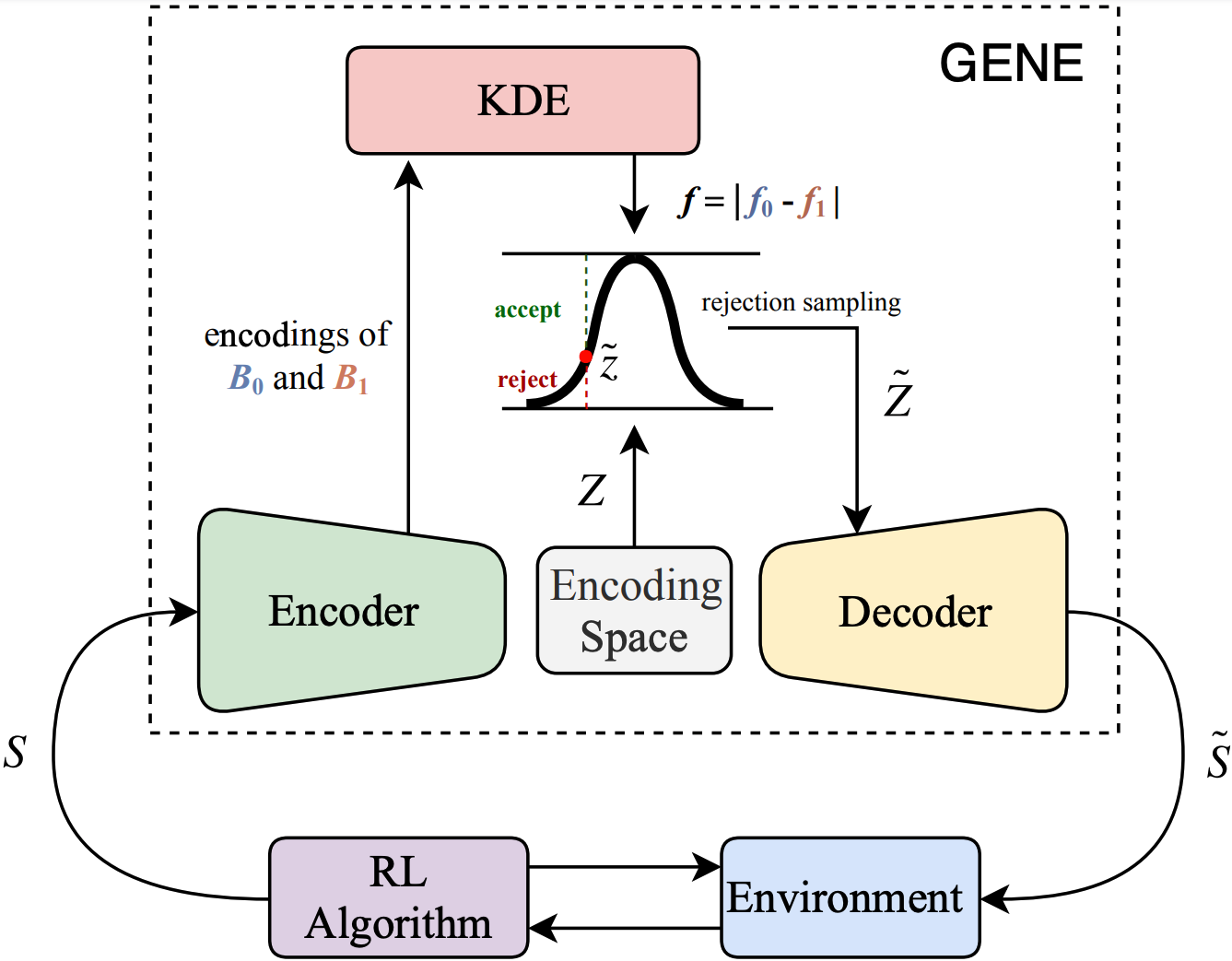 Sparse reward is one of the biggest challenges in RL. We propose a novel method called Generative Exploration and Exploitation (GENE) to overcome sparse reward. GENE dynamically changes the start state of agent to the generated novel state to encourage the agent to explore the environment or to the generated rewarding state to boost the agent to exploit the received reward signal. GENE relies on no prior knowledge about the environment and can be combined with any RL algorithm, no matter on-policy or off-policy, single-agent or multi-agent. Empirically, we demonstrate that GENE significantly outperforms existing methods in four challenging tasks with only binary rewards indicating whether or not the task is completed, including Maze, Goal Ant, Pushing, and Cooperative Navigation. The ablation studies verify that GENE can adaptively tradeoff between exploration and exploitation as the learning progresses by automatically adjusting the proportion between generated novel states and rewarding states, which is the key for GENE to solving these challenging tasks effectively and efficiently.
Sparse reward is one of the biggest challenges in RL. We propose a novel method called Generative Exploration and Exploitation (GENE) to overcome sparse reward. GENE dynamically changes the start state of agent to the generated novel state to encourage the agent to explore the environment or to the generated rewarding state to boost the agent to exploit the received reward signal. GENE relies on no prior knowledge about the environment and can be combined with any RL algorithm, no matter on-policy or off-policy, single-agent or multi-agent. Empirically, we demonstrate that GENE significantly outperforms existing methods in four challenging tasks with only binary rewards indicating whether or not the task is completed, including Maze, Goal Ant, Pushing, and Cooperative Navigation. The ablation studies verify that GENE can adaptively tradeoff between exploration and exploitation as the learning progresses by automatically adjusting the proportion between generated novel states and rewarding states, which is the key for GENE to solving these challenging tasks effectively and efficiently.
VER
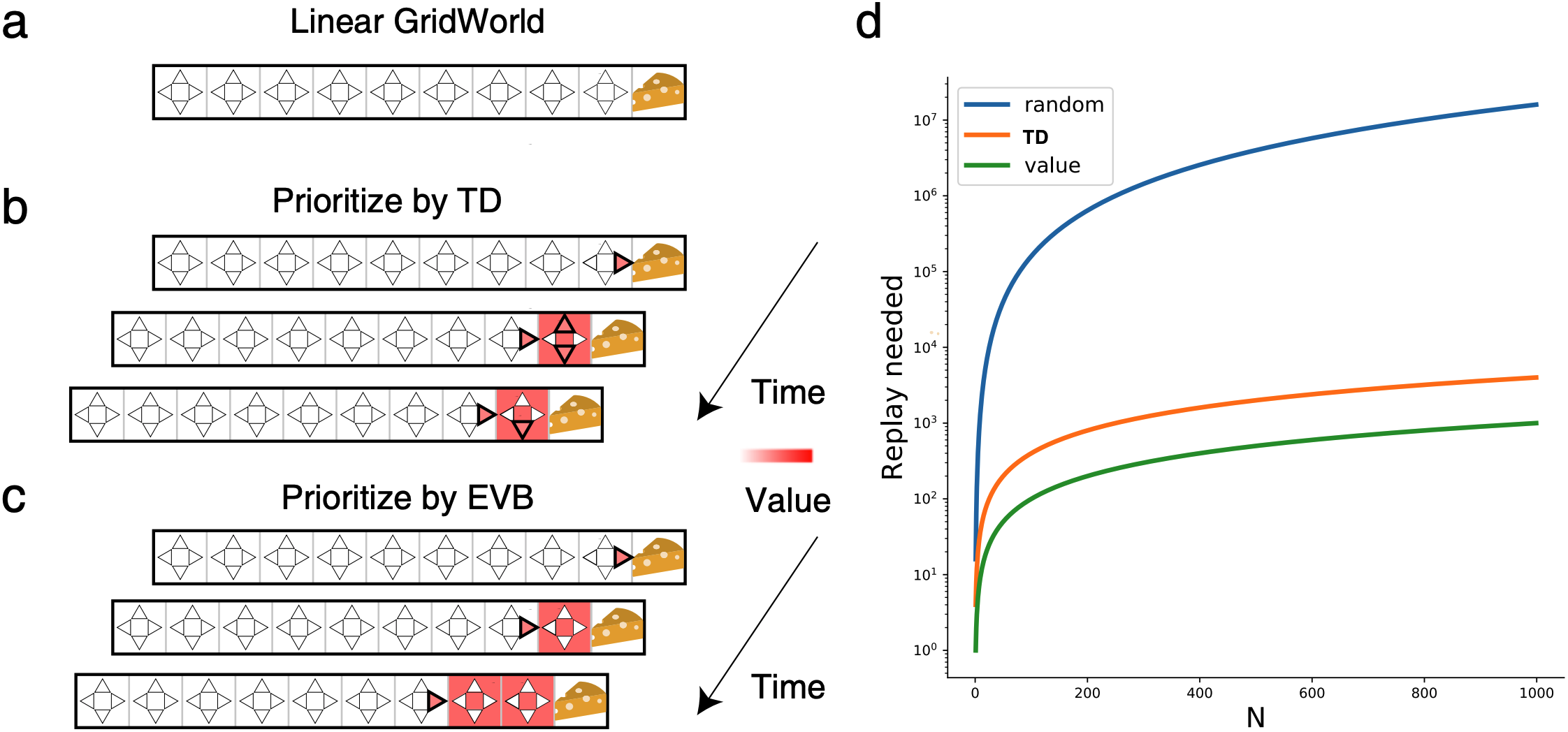 Experience replay enables off-policy RL agents to utilize past experiences to maximize the cumulative reward. Prioritized experience replay that weighs experiences by the magnitude of their temporal-difference error (|TD|) significantly improves the learning efficiency. But how |TD| is related to the importance of experience is not well understood. We address this problem from an economic perspective, by linking |TD| to value of experience, which is defined as the value added to the cumulative reward by accessing the experience. We theoretically show the value metrics of experience are upper-bounded by |TD| for Q-learning. Furthermore, we successfully extend our theoretical framework to maximum-entropy RL by deriving the lower and upper bounds of these value metrics for soft Q-learning, which turn out to be the product of |TD| and “on-policyness” of the experiences. Our framework links two important quantities in RL: |TD| and value of experience. We empirically show that the bounds hold in practice, and experience replay using the upper bound as priority improves maximum-entropy RL in Atari games.
Experience replay enables off-policy RL agents to utilize past experiences to maximize the cumulative reward. Prioritized experience replay that weighs experiences by the magnitude of their temporal-difference error (|TD|) significantly improves the learning efficiency. But how |TD| is related to the importance of experience is not well understood. We address this problem from an economic perspective, by linking |TD| to value of experience, which is defined as the value added to the cumulative reward by accessing the experience. We theoretically show the value metrics of experience are upper-bounded by |TD| for Q-learning. Furthermore, we successfully extend our theoretical framework to maximum-entropy RL by deriving the lower and upper bounds of these value metrics for soft Q-learning, which turn out to be the product of |TD| and “on-policyness” of the experiences. Our framework links two important quantities in RL: |TD| and value of experience. We empirically show that the bounds hold in practice, and experience replay using the upper bound as priority improves maximum-entropy RL in Atari games.
Publications
[AAAI'20] Generative Exploration and Exploitation
Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI), February 7-12, 2020.
(Acceptance Rate: 21%=1591⁄7737)
[ICML'22] Robust Task Representations for Offline Meta-Reinforcement Learning via Contrastive Learning
Thirty-Ninth International Conference on Machine Learning (ICML), July 17-23, 2022
(Acceptance Rate: 22%=1235⁄5630)
[NIPS'22] Double Check Your State Before Trusting It: Confidence-Aware Bidirectional Offline Model-Based Imagination
Thirty-Sixth Annual Conference on Neural Information Processing Systems (NIPS), November 28 - December 9, 2022.
(Acceptance Rate: 25.6%=2665⁄10411, spotlight)
[NIPS'22] Mildly Conservative Q-Learning for Offline Reinforcement Learning
Thirty-Sixth Annual Conference on Neural Information Processing Systems (NIPS), November 28 - December 9, 2022.
(Acceptance Rate: 25.6%=2665⁄10411, spotlight)
[ICLR'23] State Advantage Weighting for Offline RL
Eleventh International Conference on Learning Representations (ICLR), Tiny Papers, May 1-5, 2023.
[TMLR] A Survey on Transformers in Reinforcement Learning
Transactions on Machine Learning Research (TMLR), 2023.
[AAMAS'24] Towards Understanding How to Reduce Generalization Gap in Visual Reinforcement Learning
Twenty-Third International Conference on Autonomous Agents and Multiagent Systems (AAMAS), extended abstract, May 6-10.
[ICLR'24] SEABO: A Simple Search-Based Method for Offline Imitation Learning
Eighth International Conference on Learning Representations (ICLR), May 7-11, 2024.
(Acceptance Rate: 31%)
[ICML'24] Cross-Domain Policy Adaptation by Capturing Representation Mismatch
Forty-first International Conference on Machine Learning (ICML), July 21-27, 2024
(Acceptance Rate: 27.5%=2609⁄9473)
[ICML'24] Tackling Non-Stationarity in Reinforcement Learning via Causal-Origin Representation
Forty-first International Conference on Machine Learning (ICML), July 21-27, 2024
(Acceptance Rate: 27.5%=2609⁄9473)
[ACL'24] Language Model Adaption for Reinforcement Learning with Natural Language Action Space
Annual Meeting of the Association for Computational Linguistics, August 11-16, 2024.
[JAIR] Understanding What Affects the Generalization Gap in Visual Reinforcement Learning: Theory and Empirical Evidence
Journal of Artificial Intelligence Research (JAIR), 2024
[NeurIPS'24] ODRL: A Benchmark for Off-Dynamics Reinforcement Learning
Thirty-Eighth Conference on Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks, Dec. 9-15, 2024.
(Acceptance Rate: 25.3%)
[NeurIPS'24] Pre-Trained Multi-Goal Transformers with Prompt Optimization for Efficient Online Adaptation
Thirty-Eighth Conference on Neural Information Processing Systems (NeurIPS), Dec. 9-15, 2024.
(Acceptance Rate: 25.8%)
[ICLR'25] Cross-Domain Offline Policy Adaptation with Optimal Transport and Dataset Constraint
The Thirteenth International Conference on Learning Representations (ICLR), April 24-28, 2025.
(Acceptance Rate: 32.08%)
[ICLR'26] Guided Policy Optimization under Partial Observability
International Conference Learning Representations (ICLR), 2026
[ICML'26] Debiased Model-based Representations for Sample-efficient Continuous Control
Forty-Third International Conference on Machine Learning (ICML), 2026.